Case 4: A RAG Workflow
🟡 Demo:
1. Create a File block → upload your file → Create a load edge.
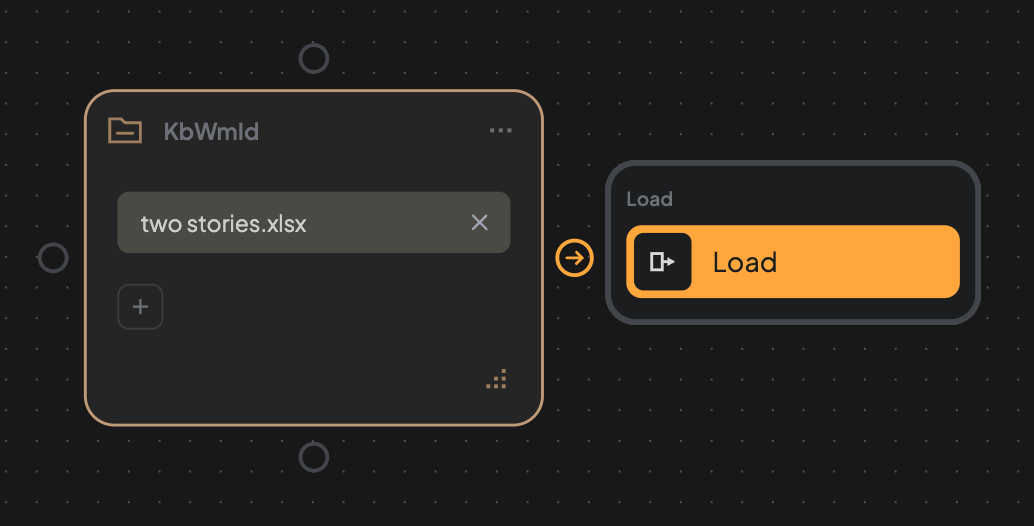
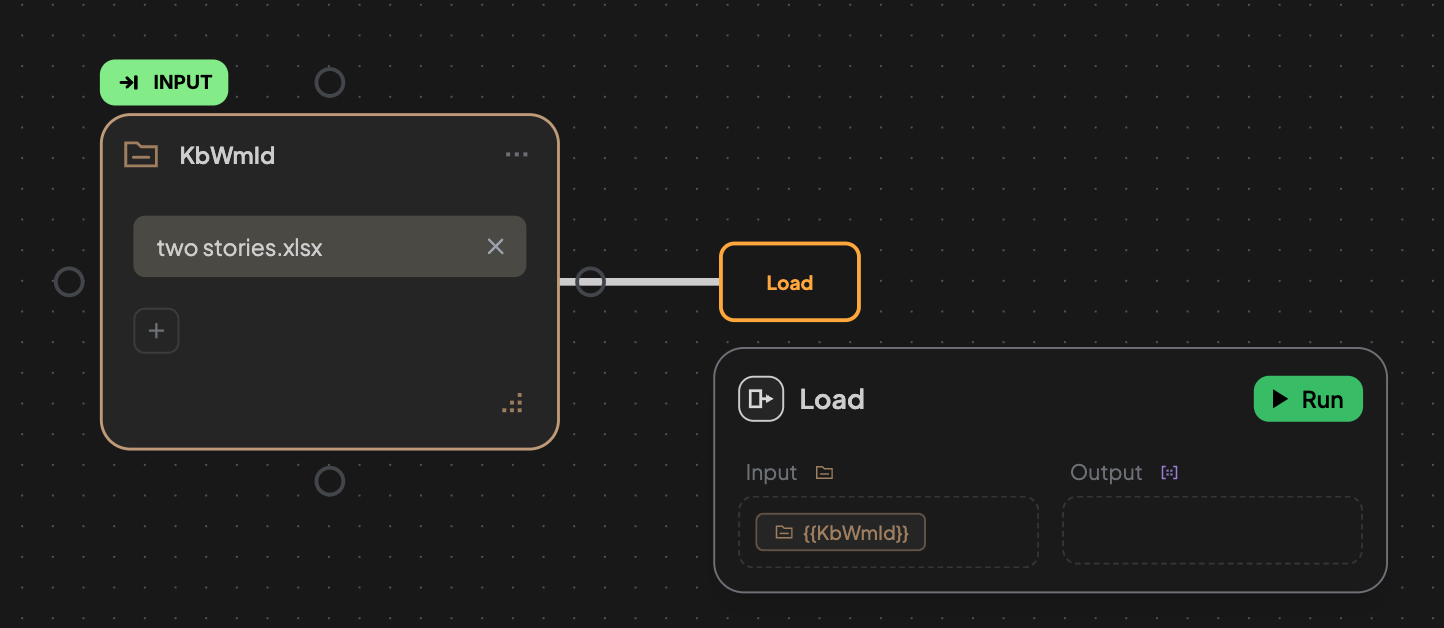
2. Run the edge to load the file.
3. Edit Structured Text.
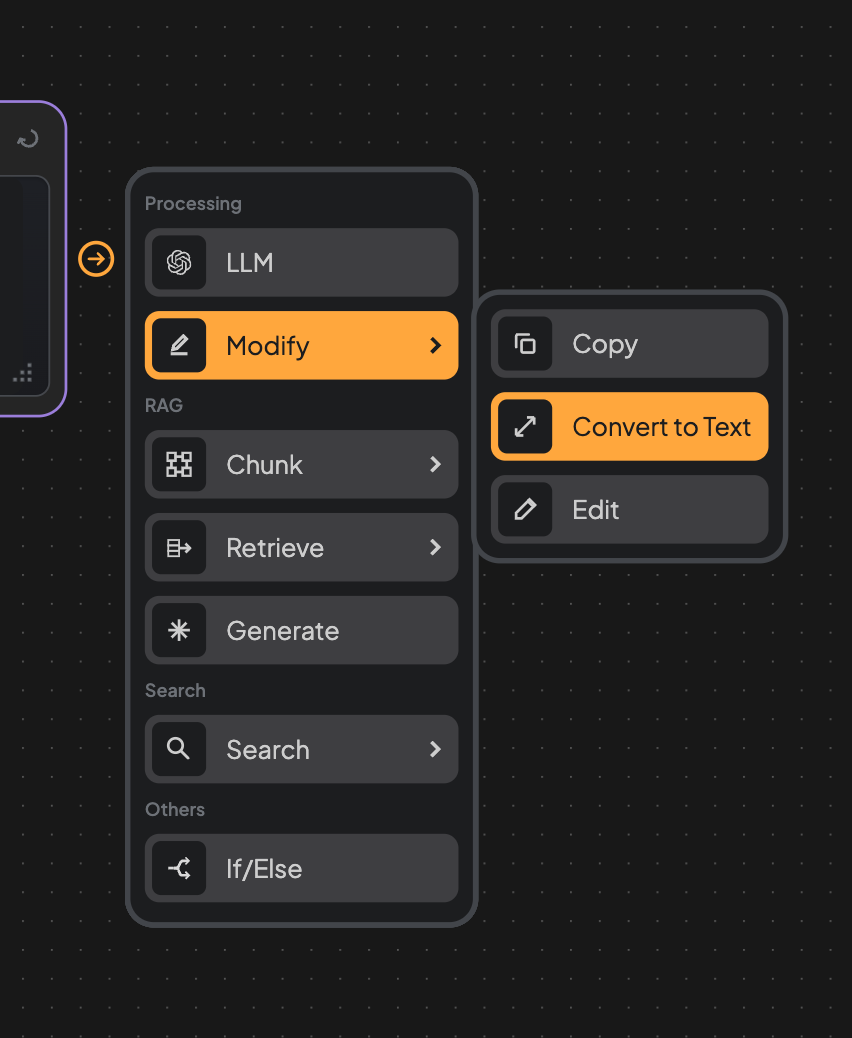
4. Create Convert to Text edge.

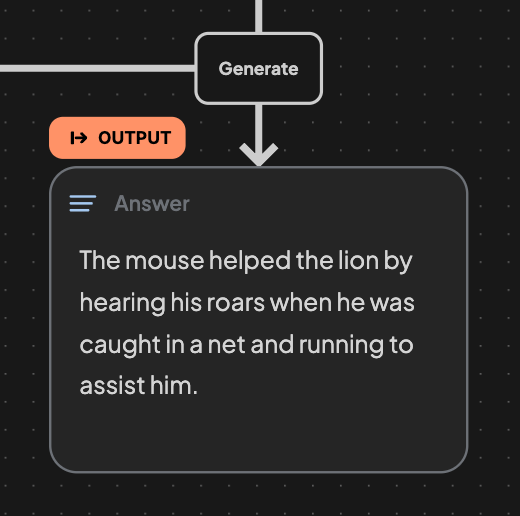
5. Generate the text.
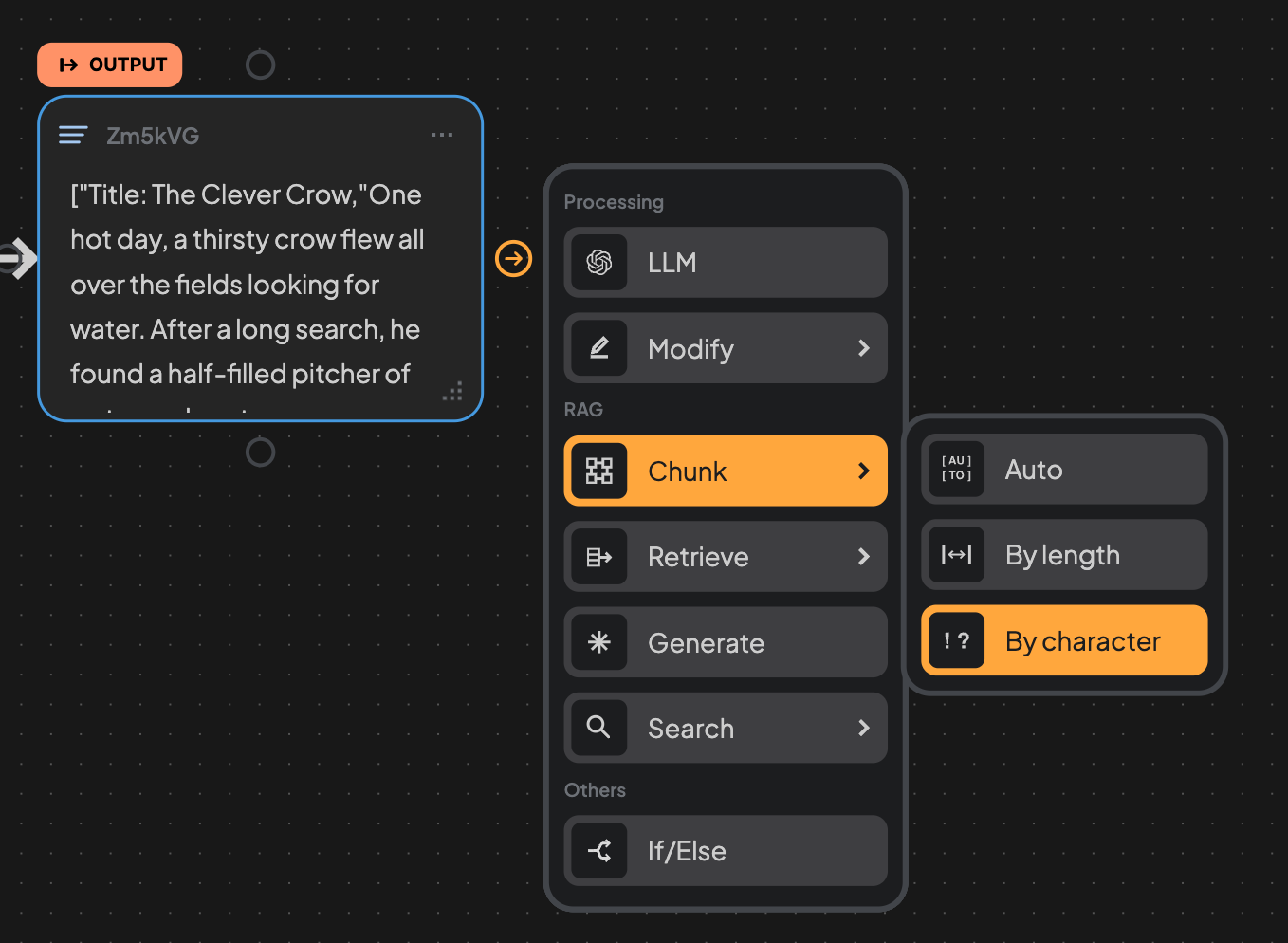
6. Create a Chunking Edge.
- Auto
- Easiest and fastest option.
- Automatically splits content by line breaks.
- No additional configuration needed.
- Best for pre-formatted content like lists or short paragraph.
- By length
- Splits content strictly by character count without using any semantic rules.
- Configurable:
- Chunk Size: Max characters per chunk.
- Overlap: Repeated characters between chunks.
- Handle Half Word: Prevents breaking words in half .(set to
Trueif using English or similar languages)
- Ideal when uniform chunk length is needed.
- By character
- Uses custom user-defined delimiters to split content.
- Configurable:
- Delimiters: Choose one or more. (e.g., comma, period, space)
- Suitable for data with predictable formatting, like CSV or semicolon-separated values.
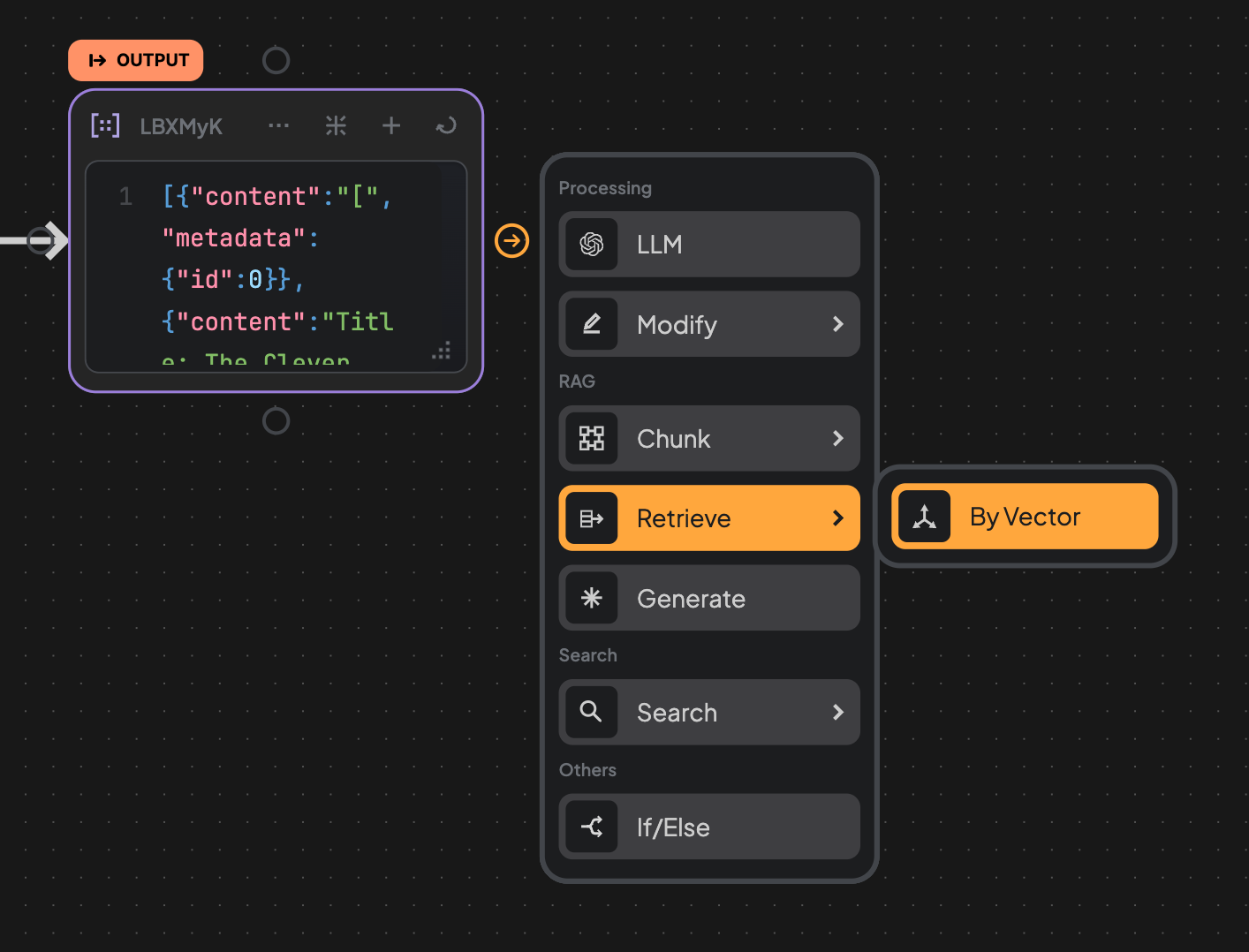
7. Run the Chunking Edge and create Retrieve Edge.
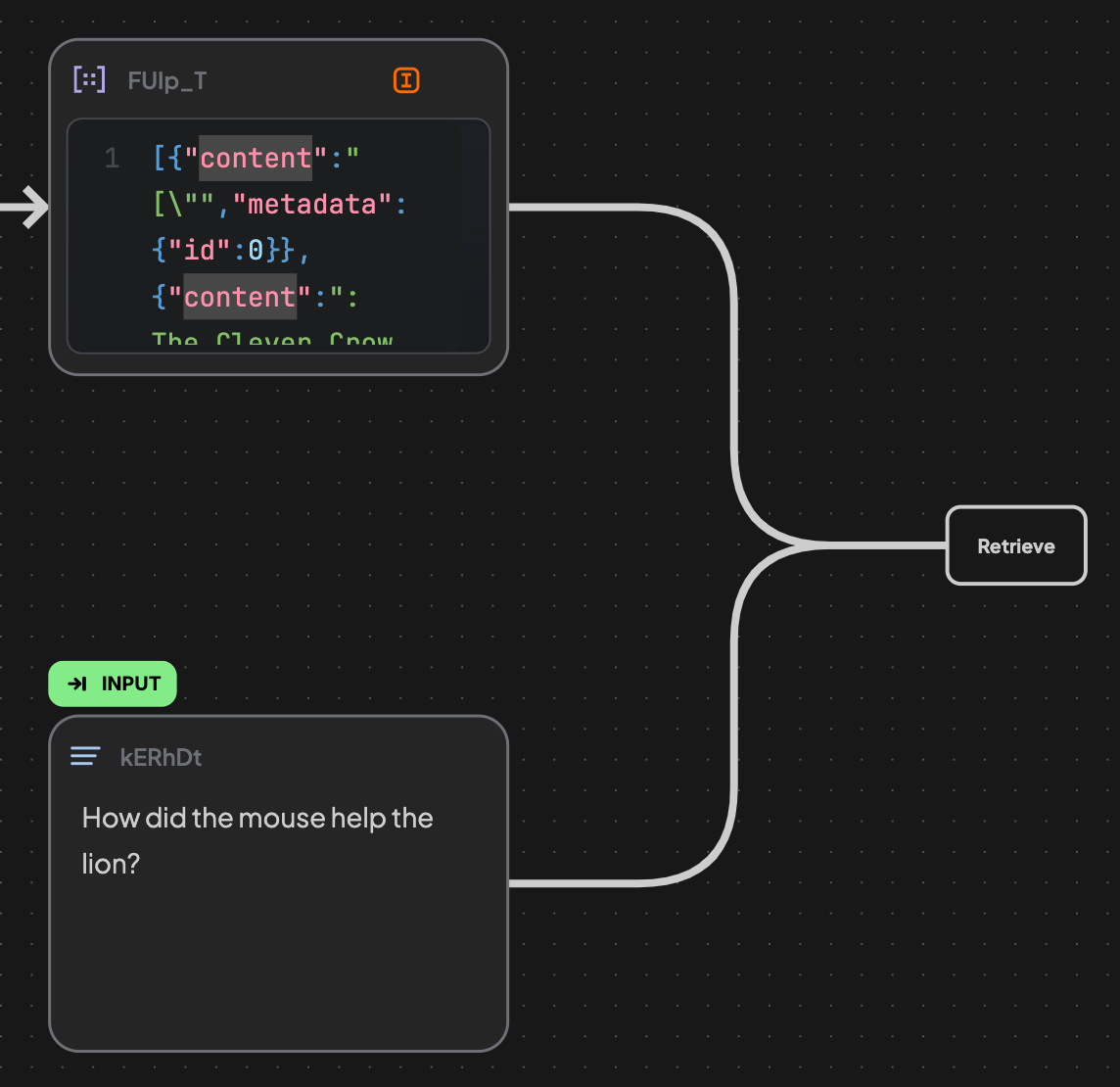
8. Create a Text Block to describe your question and connect to the Retrieve edge.
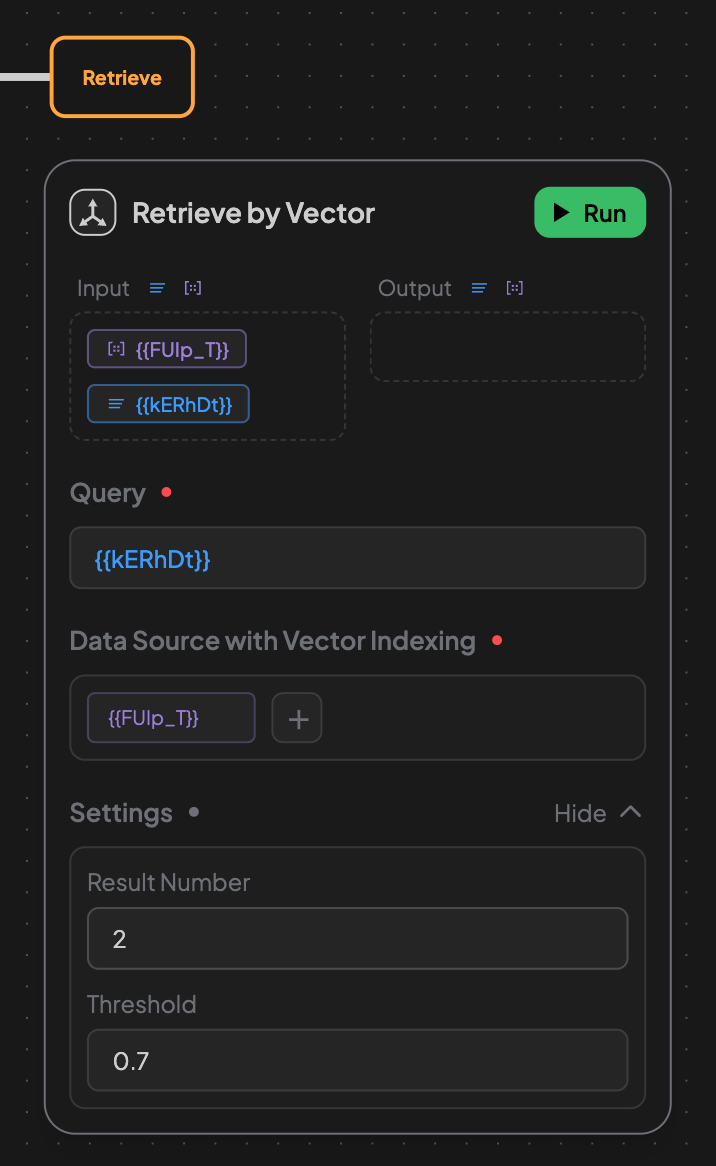
9. Modify your Retrieve Edge:
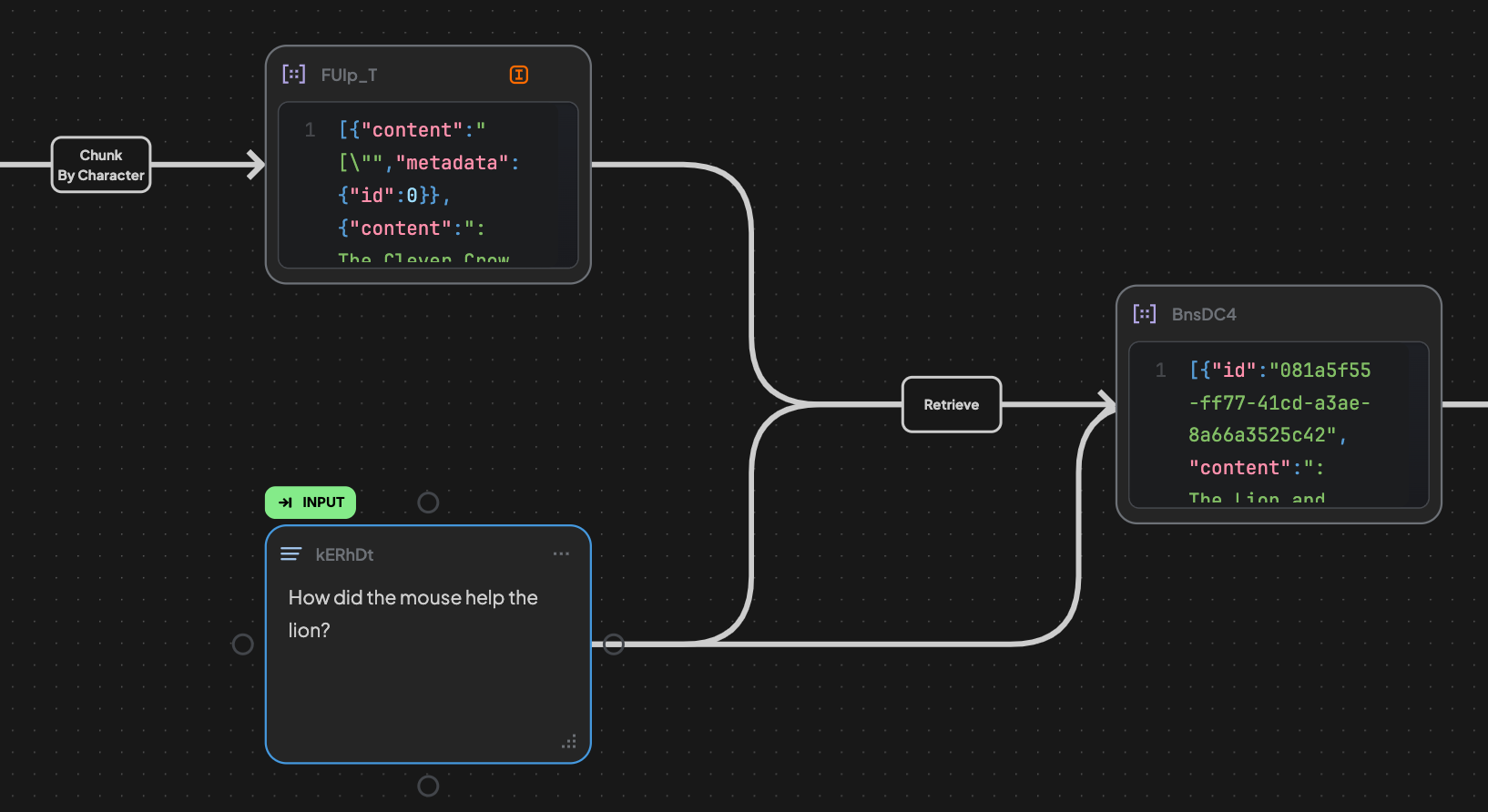
- Query: The text or structured query from user or workflow
- Data source with Vector indexing: The indexed structured content (chunks with embedding vectors)
- Settings:
- Result Number: Number of top results to return (default: 5)
- Threshold: Minimum similarity score (0–1). Default is 0.7. Results below this value will be filtered out.
10. Run the Retrieve Edge.
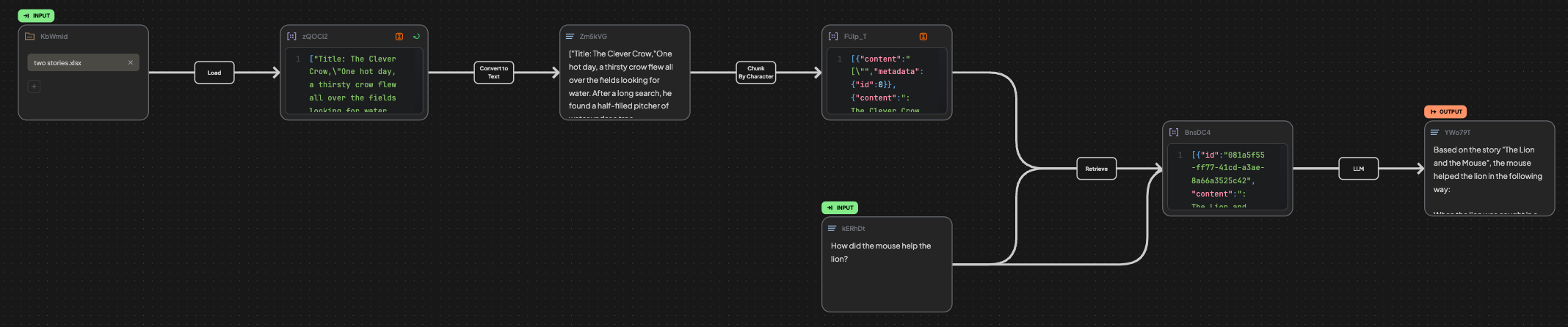
11. Generate the Answer.