Chunk Edge
Chunking is the process of splitting long documents or large text blocks into smaller, meaningful units (“chunks”) so they can be embedded and retrieved effectively.
Why Chunking is Needed:
- LLMs and embedding models have limited input sizes—splitting allows partial but precise referencing.
- Makes retrieval more fine-grained.
- Improves indexing and ranking.
Each chunk represents a small unit of knowledge, like a paragraph, a sentence, or a list item. Choosing the right chunking strategy can significantly impact the quality of the retrieved content and generated answers.
Chunk Edge in Workflow
Inputs:
- A text block containing large or unstructured data.
Outputs:
- A structured block containing an array of content chunks JSON object, with
contentandmetadatafield. - The metadata field assigns each chunk an unique id, to be used in metadata filtering in the retrieval stage.
- Note: The output content is in the same format as embedding view in a structured text block, so that you can directly indexing the structured text after using the
Chunkedge.
Chunk Modes & Configurations:
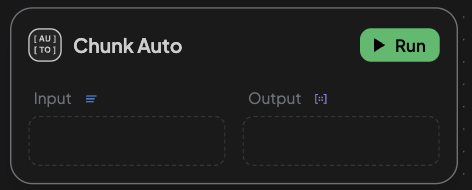
📌 Auto
- Easiest and fastest option.
- Automatically splits content by line breaks.
- No additional configuration needed.
- Best for pre-formatted content like lists or short paragraphs.
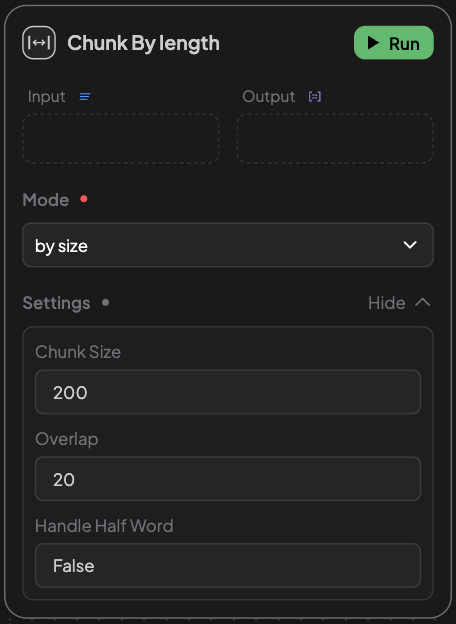
📌 By Length
- Splits content strictly by character count without using any semantic rules.
- Configurable:
- Chunk Size: Max characters per chunk.
- Overlap: Repeated characters between chunks.
- Handle Half Word: Prevents breaking words in half (set to
Trueif using English or similar languages).
- Ideal when uniform chunk length is needed.
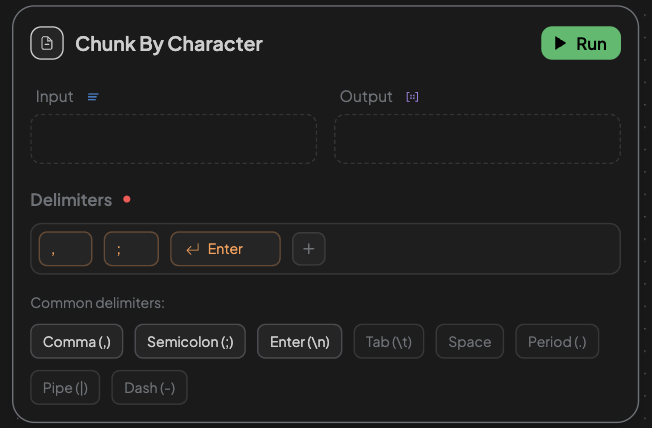
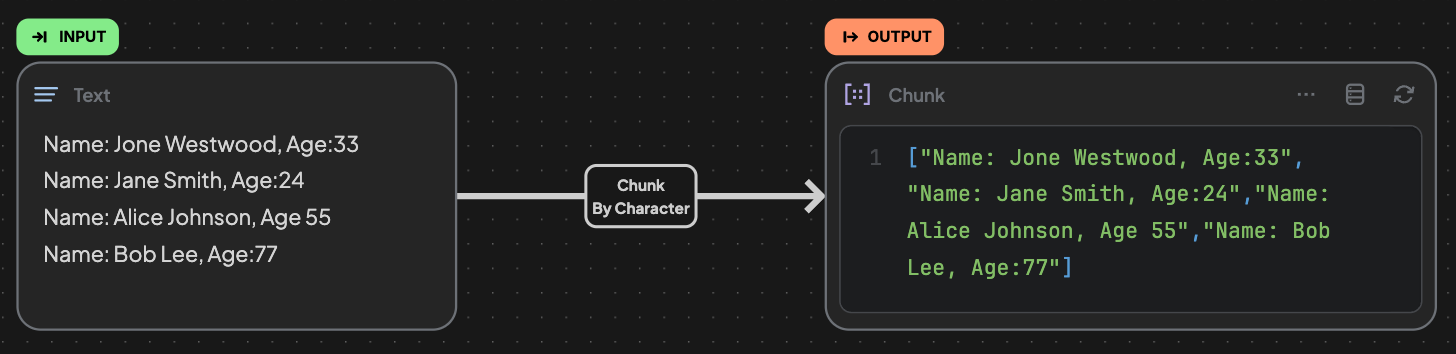
📌 By Character
- Uses custom user-defined delimiters to split content.
- Configurable:
- Delimiters: Choose one or more (e.g., comma, period, space).
- Suitable for data with predictable formatting, like CSV or semicolon-separated values.
Using these edges to prepare, retrieve, and refine content for retrieval-based workflows.