Load Edge
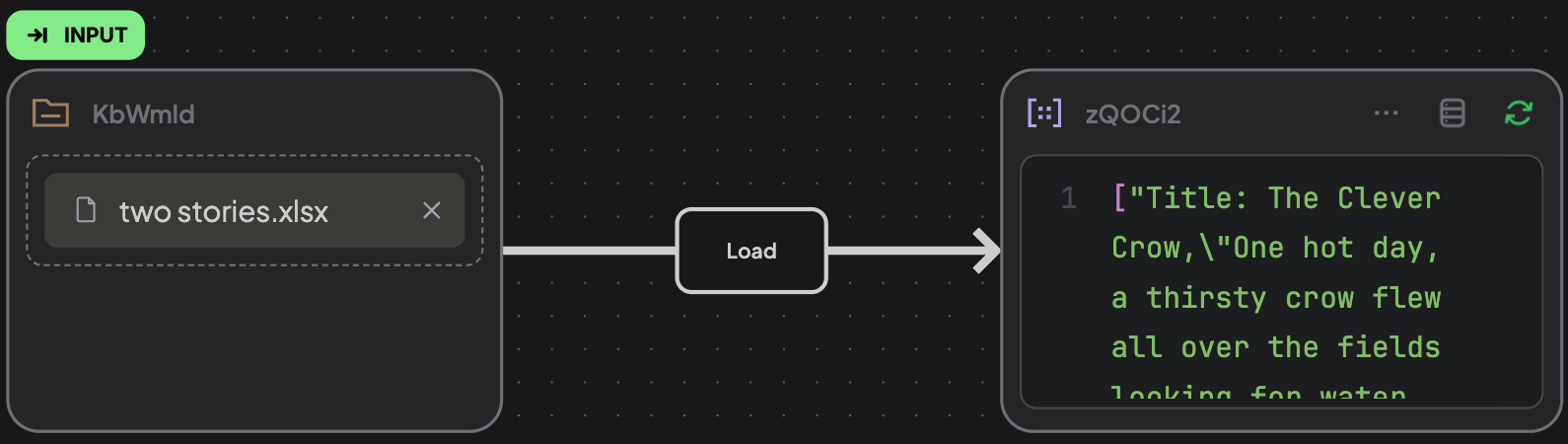
The Load Edge is used to extract and parse the content of uploaded files inside a File Block. It converts the file's raw data into structured format (Structured Text Block) for further downstream processing, which is especially helpful in automating document ingestion workflows for PDF analysis, table extraction, audio transcription, and multimedia captioning.
⚠️ This edge only works with File Blocks as input.
Supported File Types:
json,txt,doc,pdf,markdownimage,video,audiocsv,xlsx
Configuration Parameters
Each file type has its own settings to control how it's loaded and processed:
| File Type | Configurations |
|---|---|
| json | keep_json: bool — Set true to keep as object, false for raw string |
| txt / doc / markdown | auto_formatting: bool — Clean empty lines and extra spaces |
use_images: bool — OCR images in PDFpages: [start, end] (0-based) | |
| image | use_llm: bool — Use LLM (like GPT-4o) for description or fallback to OCR |
| video | use_llm: bool — LLM to describe framesframe_skip: int — How many frames to skip |
| audio | mode: small / accurate — Determines speech-to-text engine quality |
| csv / xlsx | column_range: [start, end]row_range: [start, end] — (0-based indexes) |
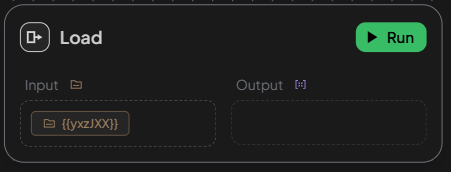
Inputs:
- A file block that contains one or more uploaded files.
Outputs:
- A structured block containing the extracted content of the loaded file(s) in sequence.